|
算力载体形态从未如今天这样多元,从老三样CPU、GPU、FPGA,到新三样NPU、TPU、DPU,各领风骚,如果算上各种小众处理器名称的术语缩写,据说26个英文字母都不够用了。于是,全球处理器龙头,算力武器库最丰富的英特尔决定终结这一乱局,提出XPU概念。所谓XPU,一如X86中的“X”,是任意的意思,XPU概念将覆盖CPU、GPU、FPGA和各种专用加速处理芯片,可处理标量、矢量、矩阵和空间架构等各种计算要素,是一个大一统的异构计算体系。 算力载体多元化肇始于数据量持续指数级增长,以及数据形态越来越多元化。现如今,大量的数据并不是易编程处理的结构化数据,处理形态多元的数据需要新算法与新算力载体支持,一种架构包打天下已经成为历史,传统解决方案耗能巨大难以支撑数据增长势头。在2021世界人工智能大会上,英特尔研究院副总裁、英特尔中国研究院院长宋继强表示,新时代科技公司需要融合不同技术,以应对全社会数字化转型带来的机遇和挑战。他说:“用不同架构去处理不同类型的数据,根据处理速度的要求、带宽的要求去优化,打组合拳好过只用一种武器解决所有问题。” 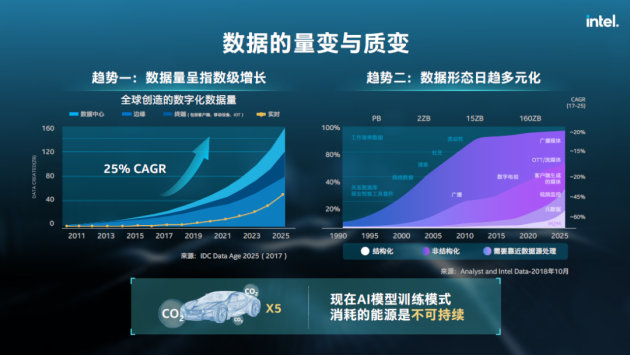
从异构计算到超异构计算 XPU概念出现离不开异构计算。异构计算是行业热点,宋继强曾撰文介绍过异构计算发展情况,并提出超异构计算概念,他认为,超异构计算将消除当前异构计算累积的弊病,打开算力增长空间,满足人工智能跳跃式发展对算力的需求。 异构计算是指在完成一个任务时,采用一种以上的硬件架构设计,将其组合在一起,以实现更优性能和功耗表现。异构计算组合方式主要包括:一体化SoC,该方式专用性最强、能耗最低、性能可能也最高,能效比非常好,但只在需求量达到一定规模时,才能达到商用化开发要求的投入产出比;分体式板卡,其优势是灵活,工程师可以根据需求随意组合,但受限于PCB走线与接插件性能,板级组合系统的功耗和带宽速度都要打很大折扣。 
传统的异构计算,已经不能满足产业应用对AI计算的需求。如下图所示,一体化SoC(红线)和分体式板卡(蓝线),分别有着比较明显的劣势。为改变传统异构计算劣势,英特尔提出了超异构计算概念。 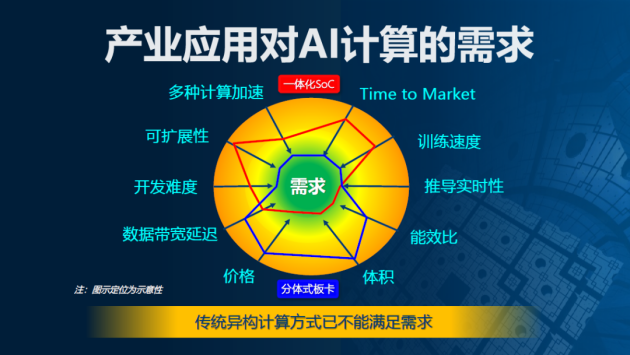
架构融合、异质集成和软件统一构成“超异构计算”三要素。架构融合,即之前提到的面向标量、矢量、矩阵和空间等不同架构相互组合,各用所长。例如,用CPU处理标量数据;用GPU处理矢量运算;用深度神经网络加速器处理块状运算,进行矩阵加速;用FPGA处理稀疏矩阵运算,可以大幅降低专用I/O和计算消耗。 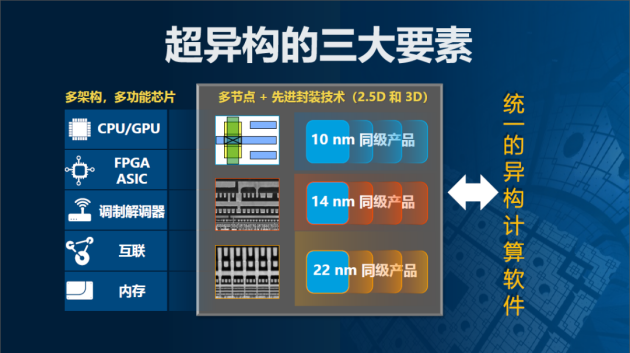
超异构计算与异构计算的主要区别体现在两点,一个是异质封装能力,一个是统一软件平台,宋继强告诉告诉探索科技(techsugar),超异构的“‘超’就超在这里。” 异质封装集成是利用半导体先进制造与封装技术,将不同节点裸芯片封装在同一颗产品里面。传统异质集成封装将芯片平铺在一起,主要有两个缺点,第一增加面积,芯片数量多时导致封装面积过大,成本增加很多;平面集成导致芯片之间连线较长,从而限制了连通带宽。立体封装(2.5D或3D封装)则解决了上述问题,将芯片像高楼一样分层堆叠,让异质集成有了极其广阔的发挥空间。 
宋继强在演进和受访时都强调,当前异质封装技术多是将处理器与存储器封在一起,目的是为了打破存储墙,增加处理器与存储器之间的带宽。在此之上,英特尔更提出了计算芯片异质封装,将不同节点工艺属性的计算芯片(Compute Die)封在同一产品内,更能发挥不同计算核心的协同效力。 多架构并存满足了应用对硬件性能的多样化需求,但不同架构开发工具和环境往往不同,一个算法到另外一个架构去实施往往要重新开发,所以异构计算增加了巨大的软件开发工作量。为解决这一异构计算的最大痛点,英特尔在2019年公布oneAPI项目,这是一个开源跨架构的编程模型,为开发者在使用CPU、GPU、FPGA和专用加速器时提供统一的开发体验。 
oneAPI的目的是降低软件开发者使用异构系统的门槛,减少重复开发工作,在硬件平台升级后,软件能以最小开发成本升级到新一代硬件平台。oneAPI开放包容,并不囿于英特尔硬件,该编程模型可以支持现在市场上主流计算硬件,目前已经有四五十家企业、大学机构宣布支持oneAPI。宋继强说:“友商的GPU和CPU,都已经有oneAPI支持的案例。” 集成光电和神经拟态计算 I/O传输瓶颈是当代大型计算系统面临的另一核心挑战。计算能力的提升,带来更多数据交互需求,当前以铜线为主的I/O互连技术应对起来就有些左支右绌,难以为继,I/O模块的尺寸和功耗都限制了计算系统的扩展。以功耗为例,增加的I/O线路会消耗大量的电能,这样计算模块分到的电能就非常少。 宋继强指出,与铜相比,光是理论上更优的互连介质。但在实际应用中,光互连技术还有光电转换效率低、光器件体积大等劣势。近年来,英特尔在光互连技术中已经取得突破性进展,逐渐消除光互连技术的缺点。例如,英特尔研究院将硅光发射、调制和接收模块等光处理中间过程模块尺寸缩小,从而将光模块和CMOS光处理器整合在一个芯片中,大幅度缩小整个系统的尺寸和功耗,从而可以用在服务器应用中。 
此外,英特尔100G硅光收发器累积出货超过400万颗;英特尔在2020年推出业界首个一体封装光学以太网交换机,集成了1.6 Tbps 的硅光引擎与 12.8 Tbps 的可编程以太网交换机。宋继强认为,集成光电技术具备变革性能力,非常值得关注。 神经拟态计算也是英特尔当前的一个研究重点。英特尔推出的神经拟态计算基础芯片Loihi,采用易扩展的存算一体架构,纯数字电路实现,拥有128个核,每个神经拟态计算内核模拟1024个神经元计算结构,共13万个神经元,每个神经元又有1000个突触连接,共1.3亿个突触。在一个应用实施中,英特尔将768个Loihi芯片连接在一起,做成规模接近1亿神经元的系统,用于科学研究。 相比深度学习算法,神经拟态计算的优势是低功耗与广适用。英特尔Loihi基于脉冲神经网络(Spike Neural Network,简称SSN),采用异步时钟,只有工作的模块耗电,不工作的部分完全不耗电。宋继强表示,与传统深度学习加速芯片相比,Loihi用电效率高1000倍。 深度学习模型基于数据驱动,针对某一个任务训练出的算法并不能轻易扩展到其他应用上。而神经拟态计算具备自学习机制,系统会根据工作时输入的数据调整参数相对应的硬件配置,这样硬件就能根据需求不同而演化出不同的模型,其灵活性是深度学习算法不能比拟的。 
宋继强介绍,Loihi没有乘加器和浮点运算单元,其运算功能由神经元来实现,开发者可以根据应用将神经元划分为视觉、语言和数学等不同区域,同时进行多模态训练。以识别榴莲为例,深度学习算法要靠成千上万张榴莲照片训练才能识别出来,而人则可以通过看、嗅、摸等多种感觉去感知榴莲,不同感知映射成为同一个符号“榴莲”。神经拟态计算就是模仿人类这种认识事物的方式来运作,宋继强说:“这就是类脑芯片真正想要达到的目标,同时进行多个输入训练,最后归结到一个符号,识别准确度高,而且功耗比较低。” 向应用要性能 从名称上来看,XPU表面是百花齐放,实质是走向统一,任意计算硬件都可以归类到XPU,从而终结无意义的概念之争;oneAPI听起来是独尊儒术,骨子里是百家争鸣,任意计算硬件都可以接入oneAPI,在不同架构下做开发的软件工程师都可以在oneAPI平台上放飞创意。超异构计算体系就是这样一个看似矛盾的开放包容与严谨统一具备的结合体。 
数据急剧增长带来计算体系概念的空前繁荣,叫什么都可以,但能否用得上、用得好才是关键,在科研中,可以极致优化某一个维度的性能,但商业化产品部署,必然是性能、开发成本和运维成本折中平衡的结果。而商业化方案的成功则离不开向应用的深度优化,即所谓垂直整合,宋继强认为,在超异构计算中,垂直整合比单一技术创新难度高很多,原因有三: 首先,垂直整合需要能够接触到实际应用的场景与真实数据,根据应用场景需求来打磨解决方案; 其次,多个领域专家要能相互配合,除了通用的算法、硬件和软件专家,还要有领域专家的鼎力支持,才能做出符合垂直应用需求的好方案; 第三,解决方案要能接受市场检验,一两套方案原型与大规模商业化部署的难度差异极大。 宋继强举例:“就像现在的一些AI系统,原型做了出来,拿到了前一两轮投资,但到后面商业化的时候,还在用原型,那就不行了。” 
垂直整合成功的案例,除了Mobileye的自动驾驶整体解决方案,还有英特尔为微软提供的搜索引擎优化方案。在搜索引擎优化应用中,对于搜索结果反馈的实时性要求极高,CPU和GPU都难以满足毫秒级硬实时要求,而由于搜索引擎算法迭代周期短,需要不断升级改版,因而ASIC也不适用,所以最终采用了英特尔CPU加FPGA组合,即典型的XPU解决方案。 垂直整合是工程和艺术的结合,因为性价比和芯片出厂后的灵活可配置是不可调和的矛盾。然而开发者总要在限定时空下去做出选择,如同英特尔推XPU和oneAPI这两个术语一样,叫什么不重要,能否落地成为大家接受的行业标准最重要。
7 k& g" b5 M: p# Z
2 n* p" f' Z* x* f. ^本文链接:http://newsoul.xinzengwj.net/thread-3055-1-1.html) C M2 o. y @' e* D% ^8 j
信息来自网络 |  推广
推广
